Файл:RAG schema.svg
Перейти до навігації
Перейти до пошуку

Розмір цього попереднього перегляду PNG для вихідного SVG-файлу: 800 × 324 пікселів. Інші роздільності: 320 × 130 пікселів | 640 × 259 пікселів | 1024 × 415 пікселів | 1280 × 519 пікселів | 2560 × 1037 пікселів | 4249 × 1722 пікселів.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Повна роздільність (SVG-файл, номінально 4249 × 1722 пікселів, розмір файлу: 76 КБ)
{kind=link}
Опис файлу
| Опис |
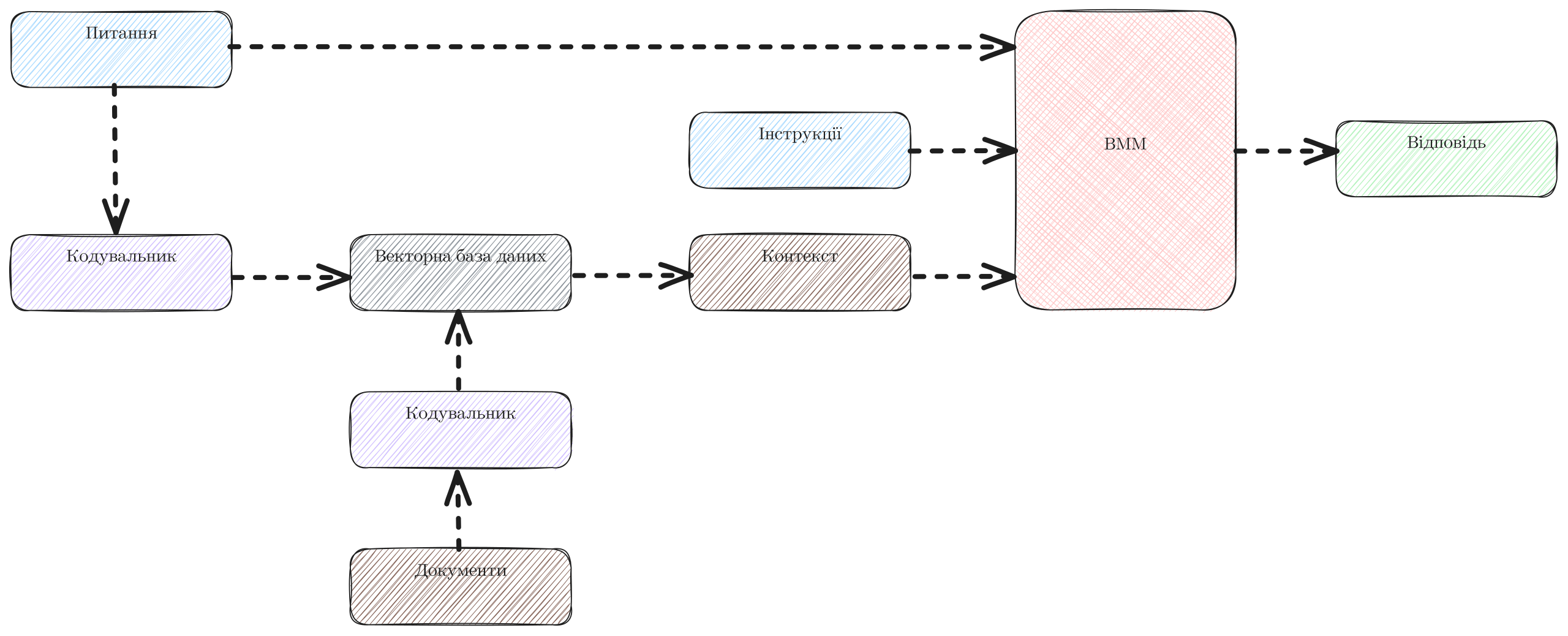
English: Diagram illustrating the two-phase process for document retrieval using dense embeddings.
Indexing Phase:
Documents are transformed into vector representations using dense embeddings.
These vectors are stored in a vector database.
Inference Phase:
The posed question is converted into a query vector using the same embedding technique.
The vector database retrieves the top four most relevant articles by computing the cosine distance between the query vector and stored document vectors.
The content of the selected articles is introduced to the Large Language Model (LLM) as context, together with the original question.
The LLM is then instructed to formulate an answer.
This process ensures efficient and relevant document retrieval based on the semantic content of queries.Polski: Diagram ilustrujący dwuetapowy proces wyszukiwania dokumentów przy użyciu gęstych osadzeń.
Faza indeksowania:
Dokumenty są przekształcane w reprezentacje wektorowe przy użyciu gęstych osadzeń.
Te wektory są przechowywane w wektorowej bazie danych.
Faza wnioskowania:
Zadane pytanie jest konwertowane na wektor zapytania przy użyciu tej samej techniki osadzania.
Wektorowa baza danych wyszukuje cztery najbardziej odpowiednie artykuły, obliczając odległość kosinusową między wektorem zapytania a przechowywanymi wektorami dokumentów.
Treść wybranych artykułów jest wprowadzana do Dużego Modelu Językowego (LLM) jako kontekst, wraz z oryginalnym pytaniem.
Następnie instruuje się LLM, aby sformułował odpowiedź.
Ten proces gwarantuje efektywne i trafne wyszukiwanie dokumentów na podstawie semantycznej zawartości zapytań.Українська: Діаграма, яка показує двоетапний процес пошуку документів з використанням щільних вкладень.
Етап індексування:
Документи перетворюють на векторні подання з використанням щільних вкладень.
Ці вектори зберігають у векторній базі даних.
Етап висновування:
Задане питання перетворюють на вектор запиту з використання того же щільного подання.
Векторна база даних знаходить чотири найвідповідніші позиції, обчислюючи косинусну відстань між вектором запиту та векторами збережених документів.
Вміст обраних позицій пропонується Великій Мовній Моделі (ВММ) як контекст, разом із первинним запитанням.
ВММ відтак кажуть сформулювати відповідь.
Цей процес забезпечує ефективний та доречний пошук документів на основі семантичного вмісту запитів. |
| Час створення | |
| Джерело | Власна робота |
| Автор | Gknor |
| SVG розвиток | switch: всі переклади зберігаються в одному й тому ж файлі. |
{kind=link}
Ліцензування
Я, власник авторських прав на цей твір, добровільно публікую його на умовах такої ліцензії:
Цей файл ліцензований на умовах Creative Commons Із зазначенням автора - Розповсюдження на тих самих умовах 4.0 Міжнародна
- Ви можете вільно:
- ділитися – копіювати, поширювати і передавати твір
- модифікувати – переробляти твір
- При дотриманні таких умов:
- зазначення авторства – Ви повинні вказати авторство, надати посилання на ліцензію і вказати, чи якісь зміни було внесено до оригінального твору. Ви можете зробити це в будь-який розсудливий спосіб, але так, щоб він жодним чином не натякав на те, наче ліцензіар підтримує Вас чи Ваш спосіб використання твору.
- поширення на тих же умовах – Якщо ви змінюєте, перетворюєте або створюєте іншу похідну роботу на основі цього твору, ви можете поширювати отриманий у результаті твір тільки на умовах такої ж або сумісної ліцензії.
Історія файлу
Клацніть на дату/час, щоб переглянути, як тоді виглядав файл.
| Дата/час | Мініатюра | Розмір об'єкта | Користувач | Коментар | |
|---|---|---|---|---|---|
| поточний | 11:37, 2 січня 2024 | 4249 × 1722 (76 КБ) | wikimediacommons>Olexa Riznyk | File uploaded using svgtranslate tool (https://svgtranslate.toolforge.org/). Added translation for uk. |
Використання файлу
Така сторінка використовує цей файл:
{kind=link}